Diffusion LLMs Are Here, what is the difference from autoregressive, Pros & Cons

While diffusion architectures revolutionized image generation, Mercury LLM from Inception Labs now brings this paradigm shift to text - achieving 10x speed boost while maintaining competitive performance. Let's dissect what makes this commercial-grade diffusion large language model (dLLM) a potential game-changer.
🏎️ Autoregressive vs Diffusion: The Architecture Race
Traditional LLMs like GPT-4 and LLama use autoregressive generation that generate text sequentially—like a pianist playing scales one note at a time. Mercury's diffusion approach works like an orchestra conductor, refining all tokens in parallel through iterative denoising.
Key Architectural Differences
| Autoregressive (GPT, Llama) | Diffusion (Mercury) | |
|---|---|---|
| Token Generation | Sequential (left-to-right) | Parallel refinement |
| Training Objective | Predict next token | Denoise full sequence |
| Hardware Utilization | 60-65% GPU efficiency | 85%+ GPU efficiency |
| Context Scaling | Quadratic complexity | Linear scaling |
⚡ Performance Benchmarks
Mercury is able to achieve over 1000 tokens/second on NVIDIA H100s. This performance is unmatched without specialized chips.
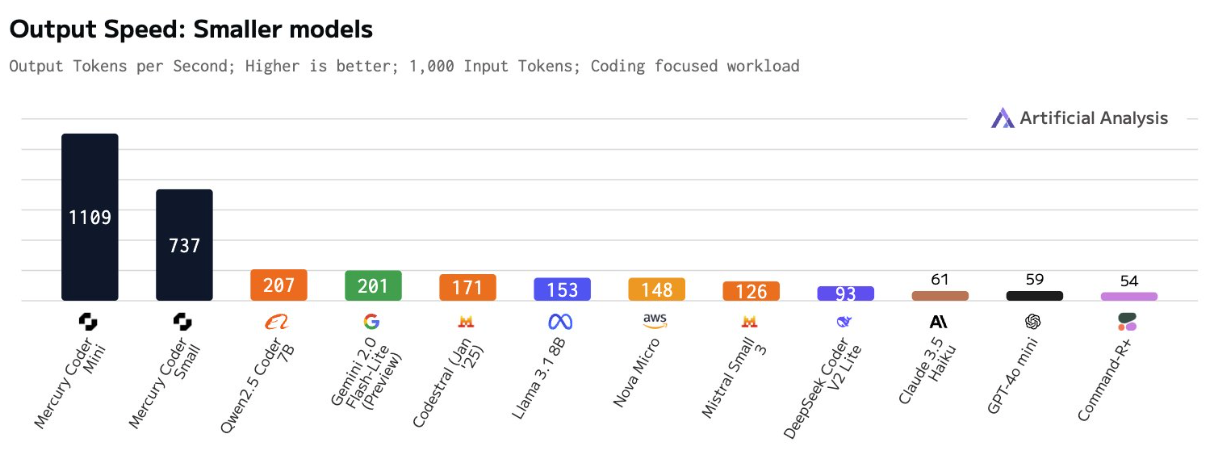
Key advantages emerge:
- Real-time coding assistance: 1000+ tokens per second
- Batch document generation: 92% batch efficiency
- Multi-agent systems: concurrent agent reasoning
⚖️ The Tradeoff Equation
While Mercury excels in speed and accuracy there are few drawbacks:

- Context Window: only 3,000 tokens
- Reasoning Depth: Struggles with multi-step logic chains
- Multi-agent systems: Inception Labs doesn't yet offer a larger model comparable with competitors state-of-art models
All that to say that this model has the potential to be different, and possibly showcase new, unique psychology, or new strengths and weaknesses. I encourage people to try it out!
— Andrej Karpathy
🔓 The Open Source Frontier: LLaDa
LLaDA also challenges the assumption that key LLM capabilities are inherently tied to autoregressive models.
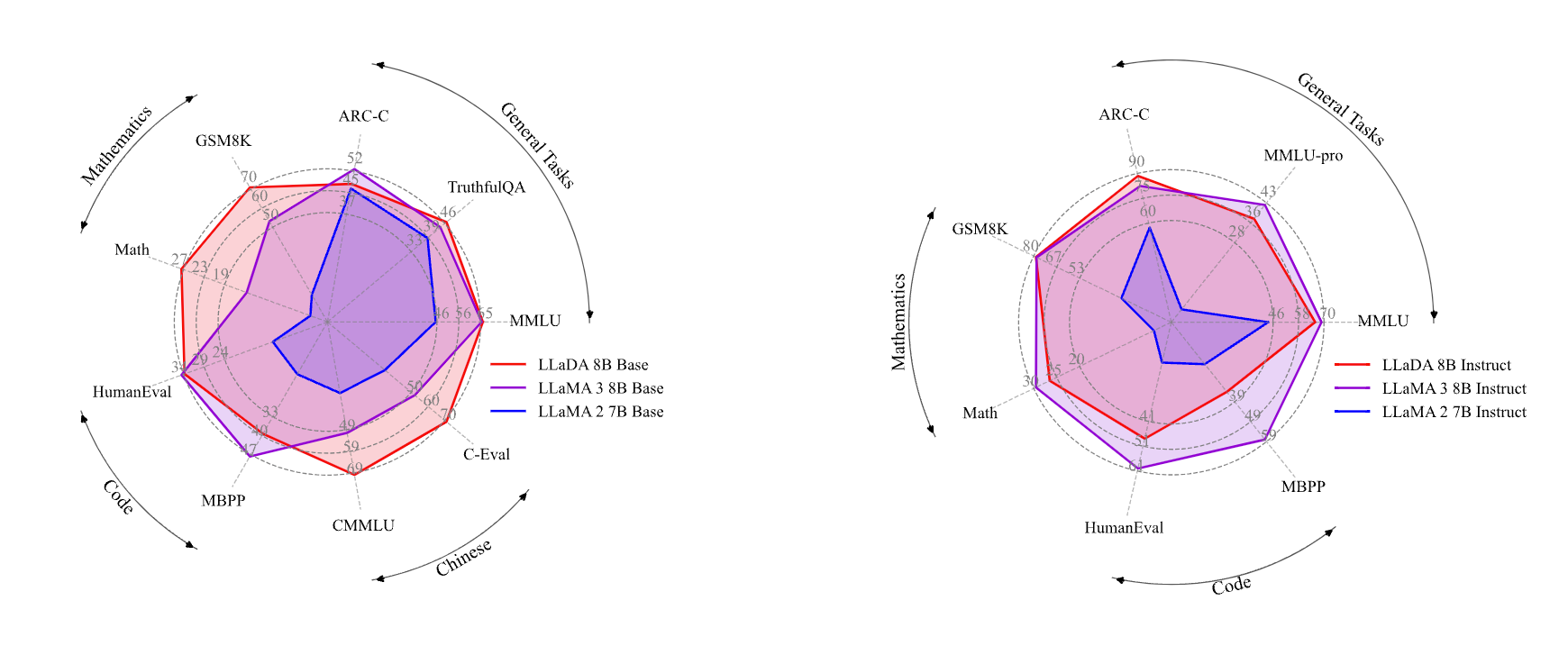
- First open-source diffusion LLM comparable to LLaMA3 8B
- Solves reversal curse better than GPT-4
- Apache 2.0 license with weights available
The Bottom Line
Diffusion LLMs isn't about beating o1 at trivia - it's about redefining what's possible in real-time AI applications. For use cases demanding lightning-fast generation with good-enough quality, diffusion architecture sets a new benchmark. While traditional LLMs still rule for deep reasoning, Mercury proves there's life beyond autoregressive transformers.
While we wait for Mercury's API to become available, DocsGPT users can experiment with the LLaDa-8B